数据挖掘概念与技术(原书第三版)--读书笔记
生活中不是缺少数据,而是缺少挖掘数据的艺术
一、Chapter 1(引论)
1.1 KDD(数据知识发现)
对于KDD,不同的人对其理解有所不同,有的将其视为DM的同义词,有的人则偏向于把DM看做KDD的一个基本步骤。根据实际项目经验来看,个人更倾向于第一种观点,KDD共由7个步骤组成,如下图1-1所示:
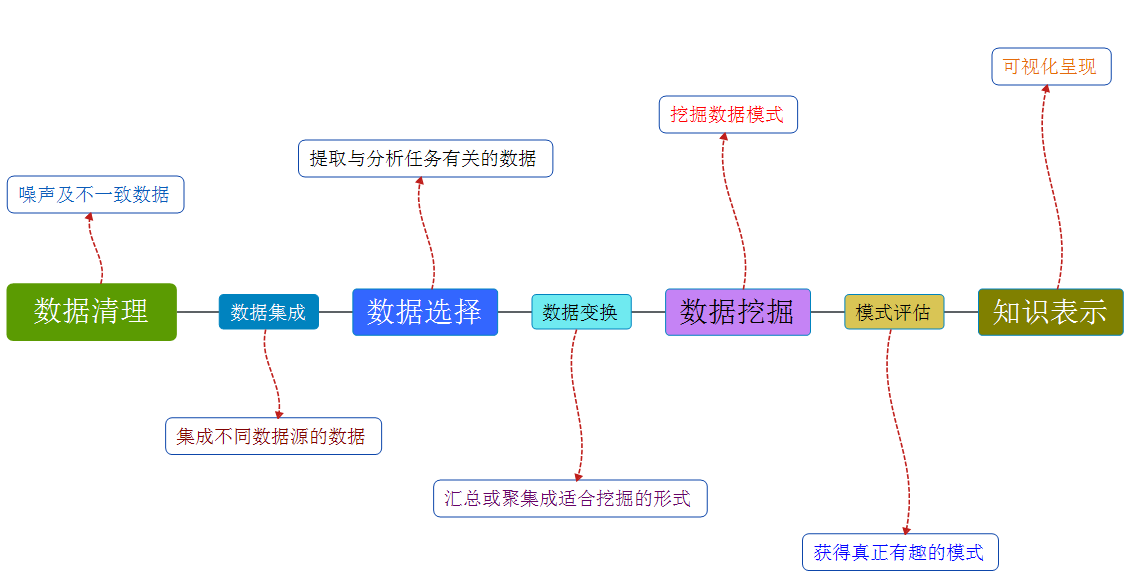
虽然上图中第五步名称也称为“数据挖掘”,但是个人认为,这里所指的数据挖掘属于狭义上的,广义上的数据挖掘不应该仅仅指对处理好的数据进行数据模式的提取,还应该包含前期非常重要的数据预处理以及后期的可视化呈现,整个流程才构成完整的“数据挖掘”,而不应该将这些连贯的过程割裂开来。有经验的同行应该都有这样的感悟,做数据挖掘也好,机器学习也罢,其实相当大一部分时间都会耗费在数据的预处理这个环节。
说明:以上仅属个人观点,请知晓,而该教材中(P9)对“数据挖掘”的定义为:
从大量数据中挖掘有趣模式和知识的过程。
数据源包括数据库、数据仓库、Web、其他信息存储库或动态地流入系统的数据。
1.2 可以挖掘什么类型的数据
理论上,数据挖掘适用于任何类型的数据,它是一种通用技术。但是在实际生产中,应用的比较多的有三种:数据库数据、数据仓库数据以及事务数据。其它的则包含比如流式数据、序列数据、图或者网络数据、空间数据、文本数据、影音数码多媒体媒体数据等等。在互联网如此发达的今天,事务数据占据着举足轻重的地位。
1.2.1 数据库数据
这类数据以传统的关系型数据库数据为代表,即使在非关系型数据库大行其道的今天,它仍然占据着主导地位,属于数据挖掘中最常见也是最为丰富的信息源。近年来随着“大数据”的热潮,非关系型数据库各领风骚,大有要盖过关系型数据库风头的趋势。
1.2.2 数据仓库
数据仓库书上的定义是:一个从多个数据源收集的信息存储库,存放在一致的模式下,并且通常驻留在单个站点上。典型的如有多个分部的大型公司,它的所有业务数据会从各个分部汇集到一起(通常是数据中心)。针对这种类型的数据,通常使用“数据立方体”(data cube)建模处理。对这类数据的深入分析就涉及到“多维数据挖掘”技术了。
1.2.3 事务数据
这类数据以典型的电商数据为代表,每一条记录被称作一个“事务”(transaction),它对应的实际场景可能是顾客在沃尔玛的一次购物,或者在携程上的一次酒店(航班、火车票)的预定等等。这类数据是我们“关联规则”挖掘的主要应用对象。其实这类数据最终的存储也是在数据库或者数据仓库中,当然也可能以文本方式存储,个人认为在该教材中将它独立成一类数据,主要还是因为它结构的特殊性以及其应用的广泛性。
1.2.4 其它数据
其它数据包含了之前提到的多媒体、图、文本等等,书中没有用太多的篇幅介绍,这里也不赘述,以后有机会碰到再用专题形式来写。对于文本类型数据不得不多说两句,这类数据在实际应用中也是比较广泛的,典型的如告警日志的挖掘。
1.3 可以挖掘什么类型的模式
介绍完可以挖掘的数据类型后,就要说一说我们的“模式”了。如果说数据的“类型”是我们的起点,那么数据“模式”则是我们的终点——所有的努力都是为了得到对我们有价值(即有趣)的“模式”。大体上来讲,针对这些“模式”的挖掘任务,可以分成两大类:描述性(descriptive)和预测性(predictive)。前者获得指定数据的“画像”,后者提供未来数据的预测。要获得这些有趣的“模式”的途径则是“数据挖掘功能”,下面对常用的挖掘功能及其对应可发现的模式类型分别介绍。
1.3.1 特征化和区分
数据特征化(data characterization)和数据区分(data discrimination)这两个术语听起来非常拗口,让人不解其意,我觉得用六个字就可以概括了:找共性、寻差异。数据挖掘虽然囊括了众多让人叹为观止的算法,但是它不同于理论数学,它有着深厚的应用背景,因此它的条条框框都对应着实际的应用场景。这里的数据特征化目的就在于提高“覆盖率”,而数据区分则在于提高“准确率”。在传统的数据分析领域,这两者往往是一对矛盾体,然而它们却被“大数据”巧妙的整合起来了。以广告业务为例,“大数据”之前的时代,为了不错过任何一位潜在的用户,我们的广告商都是采取大包围策略,强调“覆盖率”。而“大数据”时代的今天,则越来越强调“准确率”,越来越强调“精准营销”和“个性化服务”,这样看似降低了覆盖率,却反而间接的提高了用户的“覆盖率”。
数据特征化的输出模式包括了:饼图、条图、曲线、多维数据立方体、多维表等等这些抽象层次较高的模式。
数据区分的输出则是更为具体的特征描述,它包括了一些比较性的度量。
1.3.2 频繁模式挖掘及关联分析
频繁模式(frequent pattern)挖掘机关联分析通常用于相关关系而非因果关系的分析,传统的数据分析方式是“因果分析”,这种方式适用于数据集较小的情况。当数据集较大时,如果还是沿用这种方式,其成本是无法估量的。这个时候“相关分析”就应运而生了,“关联分析”方法让我们在面对海量数据集时,能够快速、准确的分析出那些看似无关而实际上却紧密联系的相关因素。“因果分析”要求数据使用者具有相关的专业背景及从业经验,而“相关分析”则没有这种限制。
频繁模式及关联分析的输出包括频繁项集、频繁序列、关联规则等。
1.3.3 分类与回归
相信接触过机器学习的人对分类(classification)与回归(regression)这两个词应该不会陌生,这两种技术在我们实际生产生活中运用广泛,主要是用来做一些预测。分类主要是用于类标签为离散型的数据,而回归则用于数值型(连续)的数据。
分类和回归的输出都是一个训练好的模型。
1.3.4 聚类
同分类和回归一样,聚类(clustering)在我们实际生产生活中也是运用广泛。聚类和分类、回归的区别在于,它并不要求事先对数据进行标定(标记)。实际中聚类和分类经常会交互使用。
聚类的输出也是一个训练好的模型。
1.3.5 离群点分析
通常来说,离群点意味着噪声数据,但是在实际应用中的一些离群点,它们却暗示了一些罕见的事件或稀有的模式。也因此针对离群点的挖掘分析,我们常称为异常挖掘。
离群点分析的输出包括稀有模式、稀有事件等等。
